自然语言和单词的分布式表示
什么是自然语言处理
自然语言处理,就是处理自然语言的科学。自然语言处理的目标就是让计算机理解人说的话,进而完成对我们有帮助的事情。
自然语言处理的相关应用
搜索引擎
百度、搜狗、Google

新闻分类

机器翻译
单词含义
我们的语言是由文字构成的,而语言的含义是由单词构成的。换句话说,单词是含义的最小单位。因此,为了让计算机理解自然语言,让它理解单词的含义可以说是最重要的事情了。
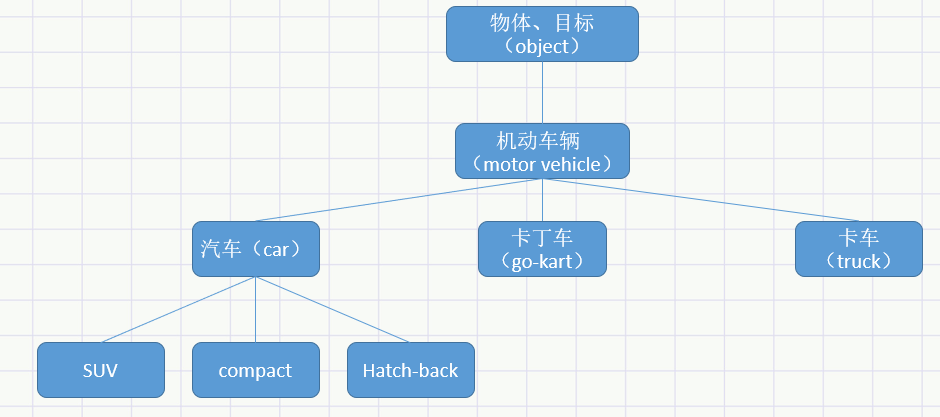
同义词词典
目前被广泛使用的并不是《新华字典》那样的常规字典,而是一种 同义词词典(thesaurus)的字典。

另外,在自然语言处理用到的同义词词典有时会定义单词之间的粒度更细的关系,比如“上位-下位”关系,“整体-部分”关系。
同义词词典的问题
难以顺应时代变化
随着时间的推移,会有新词不断的出现,不仅如此语言的含义也会随着时间的推移而变化。例如,教育部发布的新词

人力成本高
《汉语大词典》第二版收录词汇50万
据说英语词汇总数超过1000万个
无法表示单词的微妙差异
即使是含义相近的单词,也有细微的差别。甚至有一些同义词的差异让人来解释都很困难。
基于计数的方法
基于python的语料库的预处理
语料库
我们将用到语料库。简而言之,语料库就是大量的文本数据。不过,预料库并不是胡乱收集数据,一般收集的都是用于自然语言处理研究和应用的文本数据。
自然语言处理邻域有非常有名的语料库,比如Google News,中文的sogou文本分类语料库等。我们先用一个非常简单的文本作为学习的语料库,然后再处理更加实用的语料库。
1 | |
jieba分词
可以对中文文本进行分词、词性标注、关键词抽取等功能,并且支持自定义词典。
1 | |
创建单词id和单词的对应表
1 | |
转化为numpy数组
1 | |
封装为一个预处理函数
1 | |
单词的分布式表示
我们都知道世界上的颜色可以通过RGB三原色分别来表示而且知道一个颜色的RGB就至少可以知道它是哪个色系的,比如深绯(201,23,30)不知道“深绯”什么颜色,但是根据RGB可以知道至少它是红色系。而且,颜色的关联性也都体现在三个部分组成的向量中了。那假如我们也能在单词的领域构建紧凑合理的向量,可能就可以更准确的把握单词的含义。这在自然语言处理领域,称为分布式表示。
分布式假设
“某个单词的含义由它周围的单词形成”
——分布式假设
单词本身没有含义,单词含义由它所在的上下文(语境)形成。
从现在开始,我们会使用到“上下文”一词。这里所说的上下文是指单词(关注词)周围的单词。

将上下文的大小(及周围的单词有多少个)称为窗口大小
共现矩阵
关注某个单词的情况下,对它的周围出现了多少次什么单词进行计数,然后再汇总。这样的做法称为“基于计数的方法”。


表格表示作为“最终”的上下文共现的单词频数。同时,这也意味着可以用向量
[0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]表示词语“最终”
编写生成共现矩阵函数
1 | |
词向量的操作
余弦相似度
当我们通过共现矩阵将单词表示为向量之后我么就可以做很多别的操作,比如:余弦相似对(cosine similarity)
可以计算出向量间的相似度。
聚类
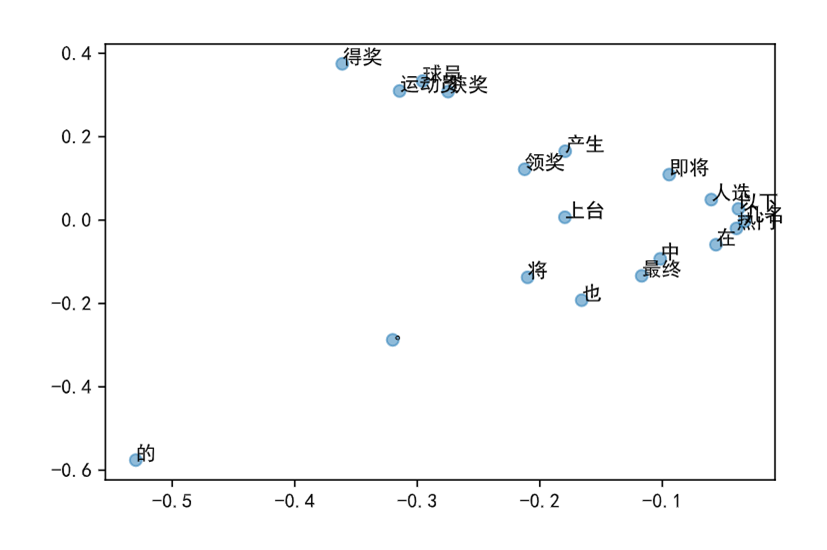
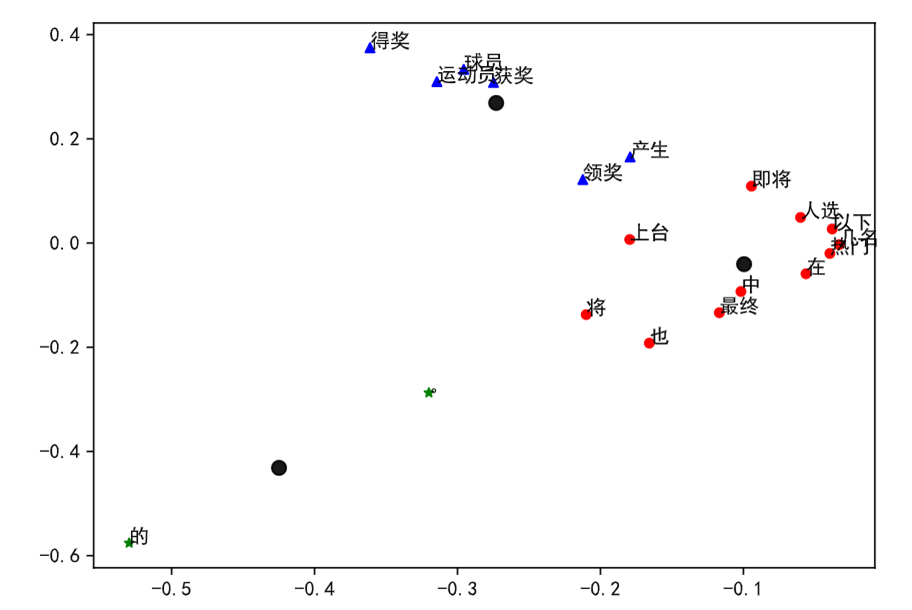
更深层次的还有新闻分类等等的操作
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!